Introduction
In the realm of AI application development services, diffusion models have emerged as a powerful tool for generating complex and high-quality outputs. These models, designed to simulate and learn from data distributions, can significantly enhance various AI applications, from image generation to data synthesis. This article provides a clear and simple guide on how to train a diffusion model effectively, making it an essential read for developers and AI enthusiasts.
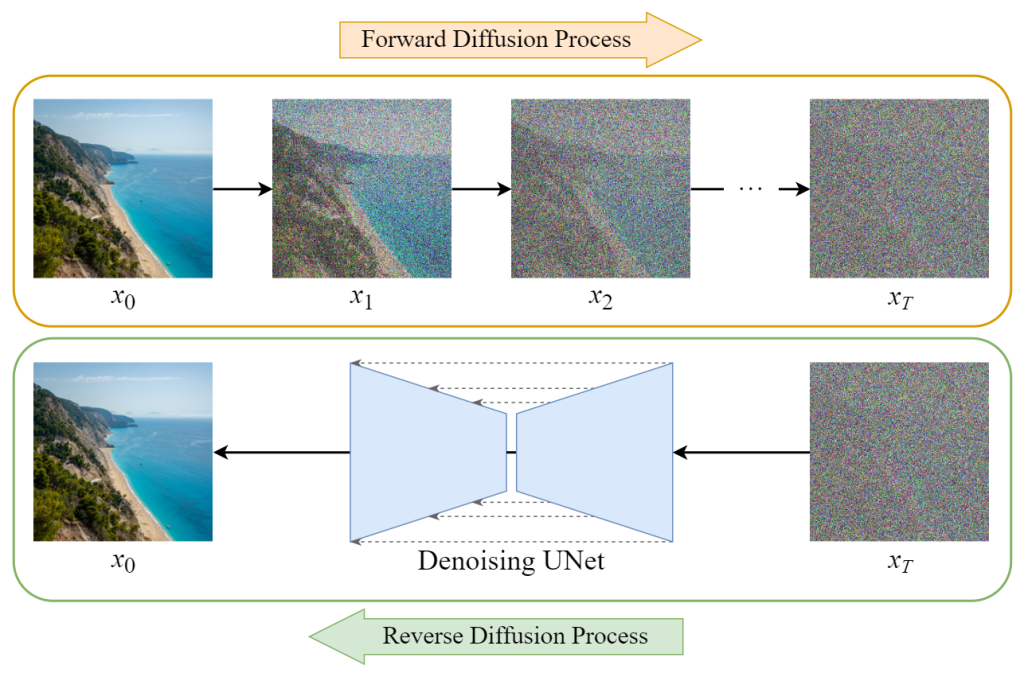
Understanding Diffusion Models
Diffusion models are a type of generative model that learns to create data by gradually adding noise to an initial distribution and then learning to reverse this process. This technique is akin to how certain physical processes work, where a substance diffuses and then reverts to its original state. In AI application development services, diffusion models are valued for their ability to produce high-quality data and their robustness in handling various types of input.
Setting Up the Training Environment
Before diving into the specifics of training diffusion models, it’s crucial to set up an appropriate environment. This includes choosing the right hardware and software tools that align with your AI application development services. Here’s a brief overview:
- Hardware Requirements: High-performance GPUs or TPUs are essential for training diffusion models due to their intensive computational needs. Ensure that your system meets the minimum specifications required for efficient model training.
- Software Tools: Utilize frameworks like TensorFlow or PyTorch, which offer extensive support for diffusion models. These platforms provide pre-built libraries and tools that streamline the training process, making them indispensable for AI application development services.
Preparing Your Data
Data preparation is a critical step in training any AI model, including diffusion models. The quality and relevance of the data directly impact the model’s performance. Here’s how to prepare your data effectively:
- Data Collection: Gather a diverse and representative dataset relevant to the problem you’re solving. For instance, if you’re developing an AI application for image synthesis, collect a wide range of images that capture different styles and contexts.
- Data Preprocessing: Clean and preprocess your data to ensure it’s suitable for model training. This includes normalization, resizing, and augmenting the data. Proper preprocessing helps the diffusion model learn more effectively and improves the quality of the generated outputs.
Configuring the Diffusion Model
Once your data is ready, configure the diffusion model to suit your specific needs. Here are the key configurations to consider:
- Model Architecture: Choose an appropriate model architecture based on your application. Common architectures include U-Net and Variational Autoencoders (VAEs), which are tailored for different types of data and tasks.
- Hyperparameters: Set the hyperparameters such as learning rate, batch size, and noise schedule. These parameters control the model’s learning process and can significantly affect the performance and quality of the generated data.
Training the Model
With the environment set and the model configured, it’s time to start training. Follow these steps to ensure a successful training process:
- Initialize Training: Start by initializing the model and loading your prepared dataset. Ensure that the model is properly configured to handle the input data and that all settings are correctly applied.
- Monitor Training: Keep track of the training progress by monitoring metrics such as loss and accuracy. This helps in identifying potential issues early and allows you to make necessary adjustments to the model or training process.
- Fine-Tuning: After initial training, fine-tune the model by adjusting hyperparameters and retraining. This iterative process helps in improving the model’s performance and ensuring that it meets the desired quality standards.
Evaluating and Testing the Model
Evaluation and testing are crucial to ensure that your diffusion model performs well in real-world scenarios. Here’s how to approach this phase:
- Evaluation Metrics: Use metrics such as Inception Score (IS) and Fréchet Inception Distance (FID) to assess the quality of the generated data. These metrics provide insights into the model’s ability to produce high-quality outputs.
- Testing on Real Data: Test the model on new, unseen data to evaluate its generalization capabilities. This step ensures that the model can handle various types of input and perform effectively in practical applications.
Deploying the Model
After successful training and evaluation, the next step is deploying the model for real-world use. This involves integrating the model into your AI application development services and ensuring it operates smoothly within your application environment.
- Integration: Incorporate the trained model into your application or service. Ensure that it interacts seamlessly with other components and provides the expected results.
- Monitoring and Maintenance: Continuously monitor the model’s performance post-deployment. Regular maintenance and updates are necessary to keep the model performing optimally and adapting to new data or changes in requirements.
Conclusion
Training a diffusion model involves a series of well-defined steps, from setting up the environment and preparing data to configuring, training, evaluating, and deploying the model. By following these guidelines and leveraging AI application development services, you can effectively harness the power of diffusion models to create innovative and high-quality AI applications. Whether you’re developing new solutions or enhancing existing ones, mastering diffusion models is a valuable skill in the evolving field of AI.

Leave a comment